


안녕하세요
llm-course 라는 Repository에 대해서 기록을 해보려고 합니다.
llm-course 에서 여러 과정들을 소개하지만
오늘은 The LLM Engineer Roadmap에 대해 짧게 살펴보겠습니다.
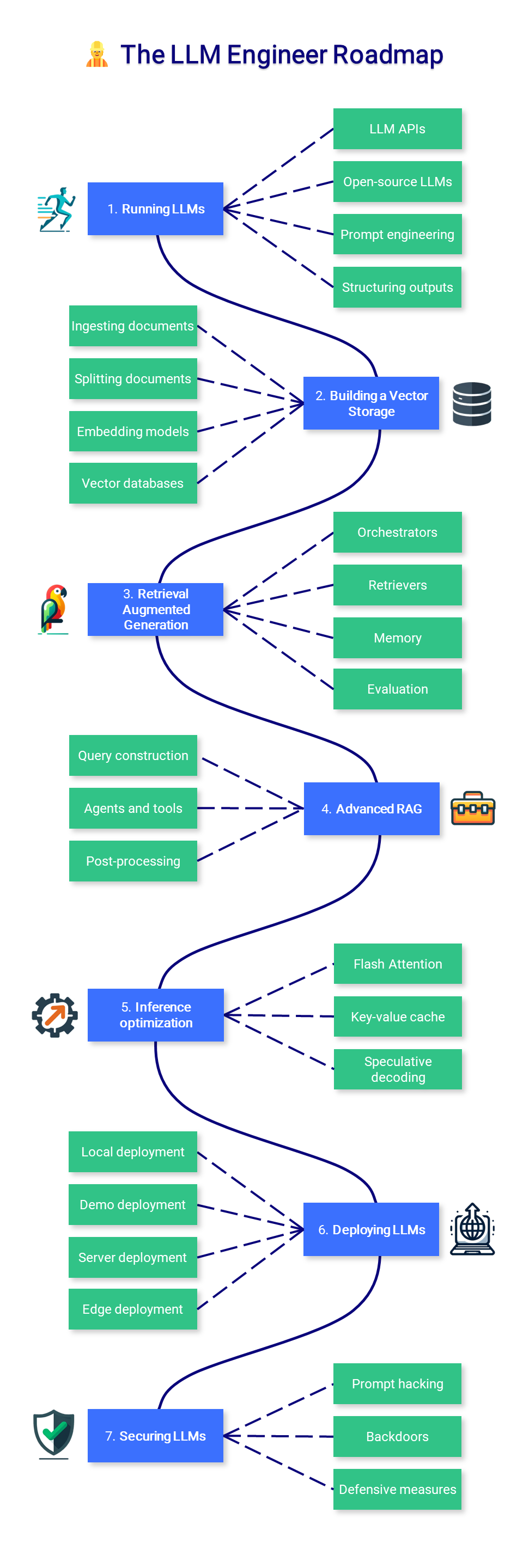
이 이미지는 대규모 언어 모델(LLM)dmf 운영하고 최적화하는 데 관련된 과정과 구성 요소를 시각적으로 나타낸 플로우 차트입니다. 이러한 모델은 자연어 처리 작업에 사용되며, 각 단계는 모델의 성능을 향상시키고 실제 세계의 문제를 해결하는 데 필요한 여러 기술과 접근 방식을 요약합니다.
이미지는 다음과 같은 7개의 주요단계를 보여줍니다.
1. Running LLMs:
- LLM API와 오픈소스 LLMs를 활용하여 사용자의 질의를 이해하고 처리합니다.
- 프롬프트 엔지니어링과 구조화된 출력을 통해 LLM의 성능을 최적화합니다.
2. Building a Vector Storage:
- 문서를 취합하고, 분할하여 임베딩 모델을 사용해 벡터 데이터베이스를 구축합니다.
- 이과정은 문서의 내용을 수치화하여 검색 가능하게 만드는 작업입니다.
3. Retrieval Augmented Generation:
- 검색 강화 생성(Retrieval Augmented Generation, RAG)을 통해 관련 정보를 검색하고, 이를 기반으로 새로운 내용을 생성합니다.
- 이 단계에서는 오케스트레이터, 검색자(Retrivers), 메모리 및 평가 등의 구성 요소가 사용됩니다.
4. Advanced RAG:
- 질의 구성, 에이전트 및 도구 사용, 후처리를 통해 RAG의 고급 기능을 구현합니다.
5. Inference Optimization:
- 추론 최적화를 위해 Flash Attention, Key-value cache, Speculative decoding 등의 기술을 사용합니다.
6. Deploying LLMs:
- 모델을 로컬, 데모, 서버, 에지 등 다양한 환경에 배포합니다.
7. Securing LLMs:
- 프롬프트 해킹, 백도어, 방어적 조치를 포함하여 모델을 보안 위협으로부터 보호합니다.
이 플로우 차트는 LLM의 운영, 최적화, 배포 및 보안에 필요한 다양한 과정과 기술을 나타냅니다. 이러한 프로세스는 모델의 효율성과 효과를 높이는 데 중점을 두며, 사용자에게 더 나은 경험을 제공하기 위한 것입니다.

steadily